setup-guide | Setup guide for Signal server & client | Encryption library
kandi X-RAY | setup-guide Summary
kandi X-RAY | setup-guide Summary
On this repository, you will find guides about Signal Setup that might help people who want to run their own signal server.
 Support
Support
 Quality
Quality
 Security
Security
 License
License
 Reuse
Reuse
Top functions reviewed by kandi - BETA
Currently covering the most popular Java, JavaScript and Python libraries. See a Sample of setup-guide
setup-guide Key Features
setup-guide Examples and Code Snippets
Community Discussions
Trending Discussions on setup-guide
QUESTION
I'm successfully using the Loqate Address Verfication control, and filter its address results down to a single country, chosen in a select control.
However, when the country code in the select is changed, I've not been able to change the country filter in the Loqate address service to use the updated value.
ANSWER
Answered 2021-Apr-27 at 14:32Looks like you're changing the wrong value here, you want to be changing the search.countries attribute within your options object.
In your above example you could do this as follows:
QUESTION
Using the Loqate Address Verification service, is there a way to programatically detect that your account is out of credit, on load of the control? Something like the code below (that I just made up)?
...ANSWER
Answered 2021-Mar-18 at 17:07The problem is that the Loqate address.js library, which calls their API, is not returning the whole error object, just the message.
This may not be an approach that is endorsed by Loqate, but you can access the original error object through the reference to the pca.Address in the 'error' listener.
You should be able to do this (in the 'error' listener function):
QUESTION
I am working on an Android Kotlin project. I am trying to install the AppInspector plugin in my project. https://app.appspector.com/58276/setup-guide. I put in the required dependencies in the Gradle file and sync them. There was not an error. But I got the error when I tried to run the app on the Emulator.
This is my project gradle file.
...ANSWER
Answered 2020-Apr-05 at 03:29I found the issue. Withing the app Gradle file. The following snippet
QUESTION
Cannot build meta-toolkit on Windows (Win10 64-bit). I followed the instructions at https://meta-toolkit.org/setup-guide.html#windows-build-guide
...ANSWER
Answered 2020-Jan-26 at 00:32Replace "--__i" with "__i = __i -1"
in file C:\some\path\msys64\mingw64\include\c++\9.2.0\bits\stl_iterator_base_funcs.h, line 183.
This worked for me! :)
QUESTION
I want to open app and pass parameters with deep linking using Electron (macOS).
Project 'electron-deep-linking-mac-win' is on GitHub.
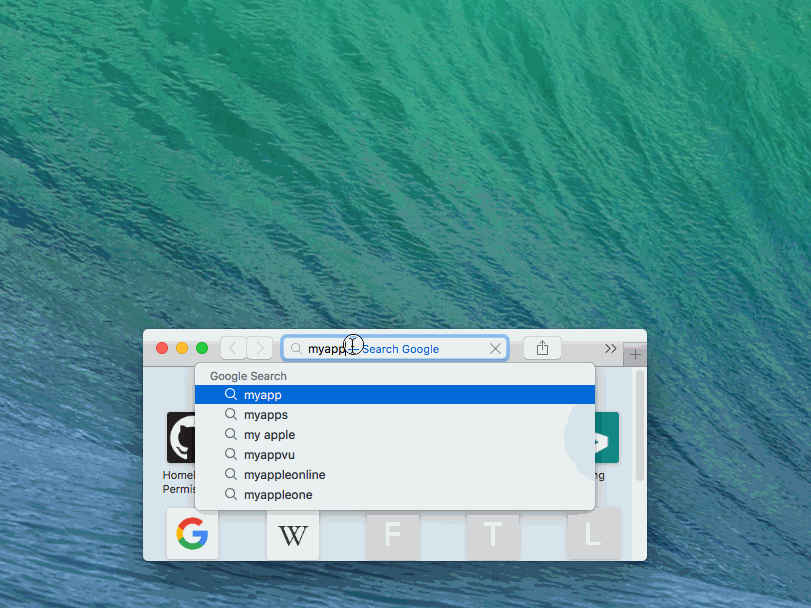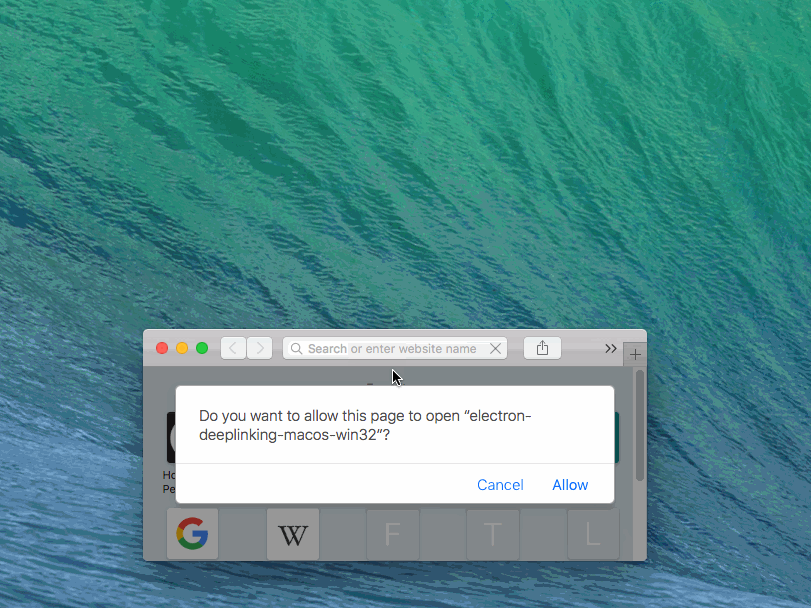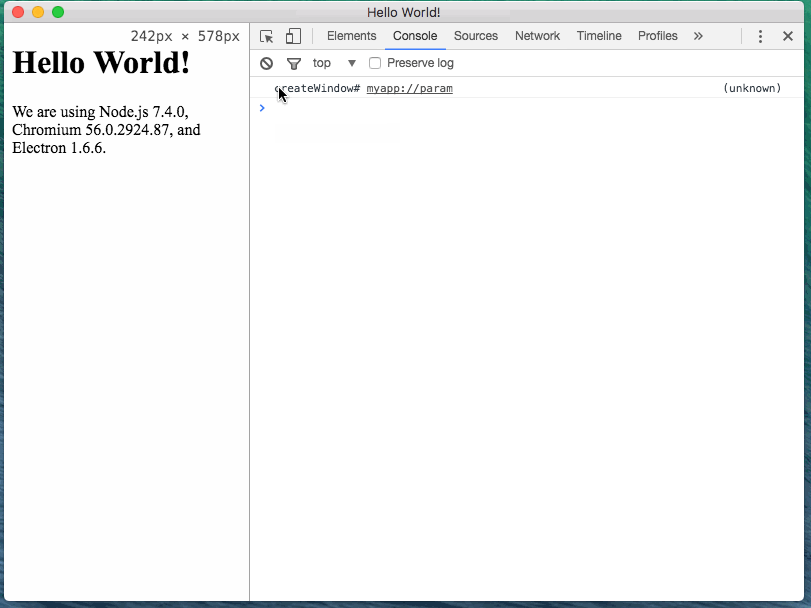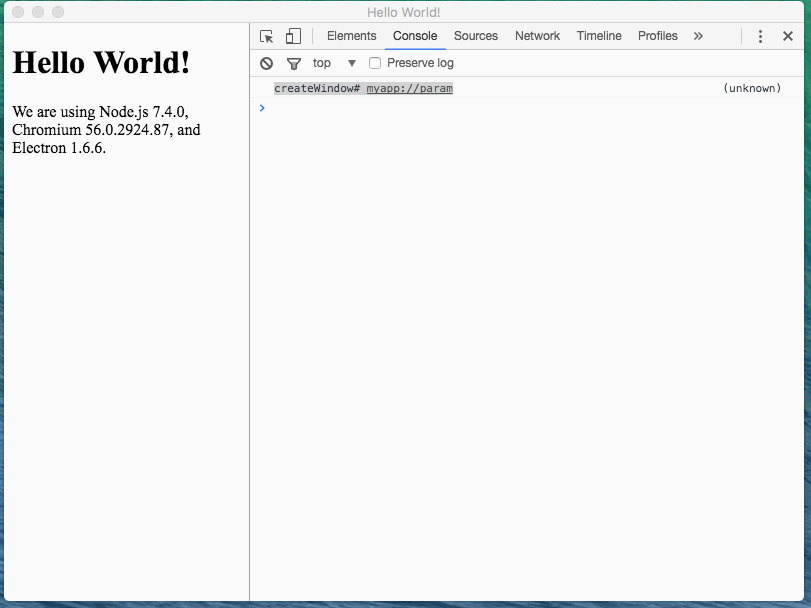{kind=link}
Edited package.json, following ‘electron-builder’ quick-setup-guide to produce mac installer:
ANSWER
Answered 2017-May-13 at 04:55You should be setting up the open-url event in the will-finish-launching callback as per the docs. I had similar weird behaviour with open-file until it was setup within the will-finish-launching callback.
You notice they've done it this way in the example you link to.
Although it mentions this under will-finish-launching, it should really mention this under the open-url and open-file docs too as its quite easy to miss.
QUESTION
I am working on a Spring Boot, MySQL, JavaFX, client server application - No web - and had a surprising effect that although I didn't altered any entity from the UI, I got an ObjectOptimisticLockingFailureException saying "Row was updated or deleted by another transaction". So I was wondering what - if not me - is updating this entity, and started to debug by switching on
...ANSWER
Answered 2019-Sep-21 at 07:31The issue is that I have a CommandLineRunner which is supposed to create test data when the database is empty. This CommandLineRunner tries to read all entities from a certain table and if nothing is returned it populates all tables. The trouble is that something is wrong with the lazy loading of the related entity. I have to investigate this and if needed I'll open a new question.
QUESTION
I followed the instructions here https://mariadb.com/kb/en/library/aws-key-management-encryption-plugin-setup-guide/#installation and added the appropriate repository for MariaDB to my Ubuntu 18.04 installation. I then tried to install the aws key management plugin, but that package can't be found. I've spent a lot of time on Google trying to figure out where it is, and I still can't figure out how to install it.
Has anyone run into this issue and/or does anyone know how I can get this plugin installed? I've downloaded the list of packages and can't find anything related to aws.
...ANSWER
Answered 2019-Mar-05 at 14:40Yes, this is intentional. Unfortunately we cannot distribute aws_key_management plugin — the fact that we did before was a mistake.
This plugin uses (and is linked with) AWS C++ SDK, which is available under the Apache 2.0 license. And this license it not compatible with GPLv2.
You can build this plugin yourself by using the cmake option -DNOT_FOR_DISTRIBUTION=1, the plugin wil be built and you'll get a warning that the result is not GPL and cannot be distributed.
If we'll find a replacement for AWS C++ SDK that uses a GPLv2 compatible license, we will be able to switch to it and distribute the plugin again.
QUESTION
I need to run a Python script within an NVIDA GPU Cloud (NGC) container on Docker in Ubuntu and I want to use Visual Studio Code to edit, run and debug it. I have installed the VS Code Docker Extension and read the documentation but none of it seems to fit my purpose.
I have followed the NGC docs, installed the NVIDIA Container Runtime for Docker (nvidia-docker2) and am now at the point where on the command line I would launch an NGC container tarball
...ANSWER
Answered 2019-May-16 at 22:06Download the NVIDA GPU Cloud (NGC) container.
Create /home/bob/foobar.py in Visual Studio Code with the VS Code Docker Extension
QUESTION
I’ve been using Gitlab with LFS just fine for a while now but somehow ran into this problem today:
...ANSWER
Answered 2018-Sep-24 at 20:46Check if this is similar to gitlab-org/gitlab-ce issue 40616:
I've verified that it is possible to push to GitLab if the LFS objects are stored elsewhere, but LFS must be disabled for the project so that the LFS validation is disabled.
Disabled LFS for the project using the API (I'm using HTTPie)
http PUT https://gitlab.com/api/v4/projects/ name= lfs_enabled=false Private-Token:
Add the
lfs.urlto the lfs config (for example GitHub)
QUESTION
I am currently testing a Kubernetes+GlusterFS+Elastic setup with VirtualBox Ubuntu VMs. I have two, one master and one node. The guide for GlusterFS here says:
"There must be at least three nodes"
I am not sure what does that mean. To elaborate a bit on what I don't understand:
- Are we talking about three Kubernetes pods running GlusterFS within the greater Kubernetes cluster, or three GlusterFS nodes within the GlusterFS cluster that exists within the Kubernetes cluster as a single pod?
- Can this requirement be met by my current setup? I was thinking of attaching 1 raw disk to the node VM with size, let's say 90GB. Then I would split that raw space to three /dev/sda2, /dev/sda3, /dev/sda4, each one 30GB, without formatting them. Now this Virtualbox VM node is also a Kubernetes node. I am assuming that Kubernetes will auto-mount those three raw spaces in the virtual world. Then, if we are talking about three Kubernetes pods, each one will have it's own virtual pod IP. As a result, I would be able to declare IP-/dev/sda# pairs in the topology file mentioned in the guide in the storage and device field respectively. In my case I will have only one device per storage IP. Does my logic make sense?
ANSWER
Answered 2019-Feb-03 at 12:53Are we talking about three Kubernetes pods running GlusterFS within the greater Kubernetes cluster, or three GlusterFS nodes within the GlusterFS cluster that exists within the Kubernetes cluster as a single pod?
Those requirements are related to the cluster quorum of GlusterFS. Those requirements implies different nodes for the High Availability GlusterFS. In the case you have a real Kubernetes cluster with different nodes you would deploy GlusterFS in each of the nodes so the data is safely replicated across all the nodes, and you would be safe in the case you loose one node.
Here you have the GlusterFS reference, hope its useful.
Can this requirement be met by my current setup? I was thinking of attaching 1 raw disk to the node VM with size, let's say 90GB. Then I would split that raw space to three /dev/sda2, /dev/sda3, /dev/sda4, each one 30GB, without formatting them. Now this Virtualbox VM node is also a Kubernetes node. I am assuming that Kubernetes will auto-mount those three raw spaces in the virtual world. Then, if we are talking about three Kubernetes pods, each one will have it's own virtual pod IP. As a result, I would be able to declare IP-/dev/sda# pairs in the topology file mentioned in the guide in the storage and device field respectively. In my case I will have only one device per storage IP. Does my logic make sense?
I think you won't be able to do this. If you look closer at the deployment manifests of GlusterFS:
Community Discussions, Code Snippets contain sources that include Stack Exchange Network
Vulnerabilities
No vulnerabilities reported
Install setup-guide
Support
Reuse Trending Solutions
Find, review, and download reusable Libraries, Code Snippets, Cloud APIs from over 650 million Knowledge Items
Find more librariesStay Updated
Subscribe to our newsletter for trending solutions and developer bootcamps
Share this Page