imc | In-Memory Java Compiler | Runtime Evironment library
kandi X-RAY | imc Summary
kandi X-RAY | imc Summary
In-Memory Java Compiler
 Support
Support
 Quality
Quality
 Security
Security
 License
License
 Reuse
Reuse
Top functions reviewed by kandi - BETA
- Loads the bytecode into a Map
- Loads the classes
- Create a ByteCodeClassLoader from a set of byte codes
- Get the byte code of this class
- Gets the class name
- Creates a new ByteCodeClassLoader from byte codes
- Returns a JavaFile for the given class
- Adds a class to be compiled
- Open a writer
- Open a stream for this class
- Load a class
- Defines a class with the given bytecode
- This method returns a hashCode of this URI
- Returns the hash code of this class
- Returns a string representation of the diagnostic
- Creates a new URI
- Compares this class to another class
- Compares this object to another
- Compares two CompilerResult objects
- Returns a hash code for this class
imc Key Features
imc Examples and Code Snippets
String source =
"public class Main {\n"+
"public static void main(String[] args) {\n"+
"System.out.println(\"hello,world!\");\n"+
"}\n"+
"}";
// Compile
InMemoryCompiler compiler = new InMemoryCompiler();
Compiler InMemoryCompiler::compile(className, classSourceCode)
returns CompilerResult
InMemoryCompiler::compile(classSourceMap)
returns CompilerResult
CompilerResult::hasErrors()
returns boolean
CompilerResult::getCompilationErrorReport()
r Community Discussions
Trending Discussions on imc
QUESTION
so I'm using lsusb | grep -n -Eo '[0-9]{1,3}' to filter the data of my command inside my terminal. The thing is, I want to filter it even more and get the two specific rows that stands for a USB bus and device number.
Here is an output for example (in here I want to have the 002 and 001 from line 1 and 001 003 from line 2):
ANSWER
Answered 2021-Apr-21 at 19:18awk might be a better choice than grep here.
QUESTION
In this paper, it is written that the 8 bytes sequential write of clwb and ntstore of optane PM have 90ns and 62ns latency, respectively, and sequential reading is 169ns.
But in my test with Intel 5218R CPU, clwb is about 700ns and ntstore is about 1200ns. Of course, there is a difference between my test method and the paper, but the result is too bad, which is unreasonable. And my test is closer to actual usage.
During the test, did the Write Pending Queue of CPU's iMC or the WC buffer in the optane PM become the bottleneck, causing blockage, and the measured latency has been inaccurate? If this is the case, is there a tool to detect it?
...ANSWER
Answered 2021-Mar-30 at 03:34https://www.usenix.org/system/files/fast20-yang.pdf describes what they're measuring: the CPU side of doing one store + clwb + mfence for a cached write1. So the CPU-pipeline latency of getting a store "accepted" into something persistent.
This isn't the same thing as making it all the way to the Optane chips themselves; the Write Pending Queue (WPQ) of the memory controllers are part of the persistence domain on Cascade Lake Intel CPUs like yours; wikichip quotes an Intel image:
{kind=link}
Footnote 1: Also note that clwb on Cascade Lake works like clflushopt - it just evicts. So store + clwb + mfence in a loop test would test the cache-cold case, if you don't do something to load the line before the timed interval. (From the paper's description, I think they do). Future CPUs will hopefully properly support clwb, but at least CSL got the instruction supported so future libraries won't have to check CPU features before using it.
You're doing many stores, which will fill up any buffers in the memory controller or elsewhere in the memory hierarchy. So you're measuring throughput of a loop, not latency of one store plus mfence itself in a previously-idle CPU pipeline.
Separate from that, rewriting the same line repeatedly seems to be slower than sequential write, for example. This Intel forum post reports "higher latency" for "flushing a cacheline repeatedly" than for flushing different cache lines. (The controller inside the DIMM does do wear leveling, BTW.)
Fun fact: later generations of Intel CPUs (perhaps CPL or ICX) will have even the caches (L3?) in the persistence domain, hopefully making clwb even cheaper. IDK if that would affect back-to-back movnti throughput to the same location, though, or even clflushopt.
During the test, did the Write Pending Queue of CPU's iMC or the WC buffer in the optane PM become the bottleneck, causing blockage, and the measured latency has been inaccurate?
Yes, that would be my guess.
If this is the case, is there a tool to detect it?
I don't know, sorry.
QUESTION
I have an Intel(R) Core(TM) i7-4720HQ CPU @ 2.60GHz (Haswell) processor. I need to retrieve the number of accesses to each DRAM rank, over time, to estimate its power consumption. Based on page 261 of the chipset documentation (i.e., Datasheet, volume 2 (M- and H-processor lines)), I could use the 32-bit value in register, RAM—DRAM_ENERGY_STATUS, as a DRAM energy estimation. But I need rank-level energy estimates. I could also use core and offcore DRAM access performance counters to estimate power consumption, but, as mentioned before, I need per-rank statistics. Besides that, they report whole-system stats, while energy is calculated per-rank. They also do not report many DRAM accesses.
Therefore, IMC counters (which are uncore counters) should be the ideal choice. Perf does not support per-rank counters. I tried to use PCM-Memory to access IMC counter information. But /sys/bus/event_source/devices/uncore_imc is not mounted by the kernel (the version is 5.0.0-37-generic) and the tool does not detect the CPU. I tried to access uncore performance counters, manually. Whole-system DRAM access counters are documented, here (They were not documented in the above-mentioned chipset manual). I can retrieve total DRAM read and write accesses using these counters. But, there is no information about channel or rank-level access stats. How can I find the offset associated with these counters? Should I use trial and error?
P.S.: This question is also asked at Intel Software Tuning, Performance Optimization & Platform Monitoring Forum.
...ANSWER
Answered 2021-Mar-12 at 16:57The MSR_DRAM_ENERGY_STATUS always reports an estimate of the energy consume by all memory channels. There is no easy way to break it into per-rank energy. This register reports a highly accurate estimate on Haswell.
The 5.0.0-37-generic kernel is an Ubuntu kernel and does support the uncore_imc/data_reads/ and uncore_imc/data_writes/ events on Haswell, which represent a data read CAS command and a data write CAS command from the IMC, respectively. A full cache-line read and a full cache-line write transactions cause a single bursty 64-byte transaction on the memory bus to a single rank. A partial read is also executed as a single full-line read on the bus, but a partial write may require a full line read followed by a full line write due to restrictions in the protocol. Partial writes are generally negligible.
The uncore_imc/data_reads/ and uncore_imc/data_writes/ events occur for requests targeting DRAM memory generated by any unit, not just cores. These names are given by perf and they correspond to UNC_IMC_DRAM_DATA_READS and UNC_IMC_DRAM_DATA_WRITES, respectively, which are mentioned in the Intel article you've cited. The other three events mentioned there allow you count requests (not CAS commands!) for each of the three possible sources separately (GT, IA, and IO). You won't find them listed under /sys/bus/event_source/devices/uncore_imc/events on your old kernel. They are supported in perf starting with mainstream kernel v5.9-rc2.
By the way, PCM does support these events as well, which it uses to report read and write bandwdith over all channels, but you should use the tool pcm.x, not pcm-memory.x, which only works on server processors.
A Haswell H-processor line processor has a single on-die memory controller with two DDR3L 64-bit channels. Each channel can contain zero, one, or two DIMMs with a total capacity of up to 32 GBs over all channels. Moreover, each DIMM can contain up to two ranks, so a single channel can contain anywhere between zero and four ranks. The i7-4720HQ is a high-end mobile processor. You're probably on a laptop with 8 GBs or 16 GBs of memory. If the memory topology was not changed since purchase, it probably has only two 4GB or 8GB DIMMs, one in each channel, with one remaining free slot per channel available for expansion if desired by the user. This means that there are either one or two ranks per channel.
You can approximate the number of accesses to each rank given the knowledge of how physical addresses are mapped to ranks. If each channel is populated with a single rank DIMM of the same capacity, the mapping is simple on your processor. Bit 6 of the physical address (i.e., the seventh bit) determines which channel, and therefore which rank, a request is mapped to. You can collect a set of samples of physical addresses of requests at the IMC by running perf record on MEM_LOAD_UOPS_L3_MISS_RETIRED.LOCAL_DRAM with the --phys-data option. Obviously this set of samples may only be representative of core-originated retired loads that reach the IMC, which are a small subset of all requests at the IMC.
It appears to me that you want to measure the number of memory accesses per rank in order to estimate the the per-rank energy from the total DRAM energy, but this is not trivial at all for the following reasons:
- Not all CAS commands are of the same energy cost. Precharge and activate commands are not counted by any event and may consume significant energy, especially with high row buffer miss rates.
- Even if there are zero requests in the IMC, as long as there is at least one active core, the memory channels are powered and do consume energy.
- The amount of time it takes to process a request of the same type and to the same address may vary depending surrounding requests due to timing delays required by rank-to-rank turnarounds and read-write switching.
Despite of all of that, I imagine it may be possible to build a good model of upper and lower bounds on per-rank energy given a representative estimate of the number of requests to each rank (as discussed above).
The bottom line is that there is no easy way to get the luxury of per-rank counting like on server processors.
QUESTION
in a python exercise I am asked to get the minimum value of a column dataframe called 'IMC' and show also the columns name, position, IMC and club of the player with less IMC. I am trying something like these but it is not working at the time.
...ANSWER
Answered 2021-Jan-07 at 15:14From the way you have phrased your question, I think the following code might do the job for you?
QUESTION
I am working on an Android app.
This is one function inside a fragment:
...ANSWER
Answered 2020-Oct-27 at 20:06Making use of callbacks :
QUESTION
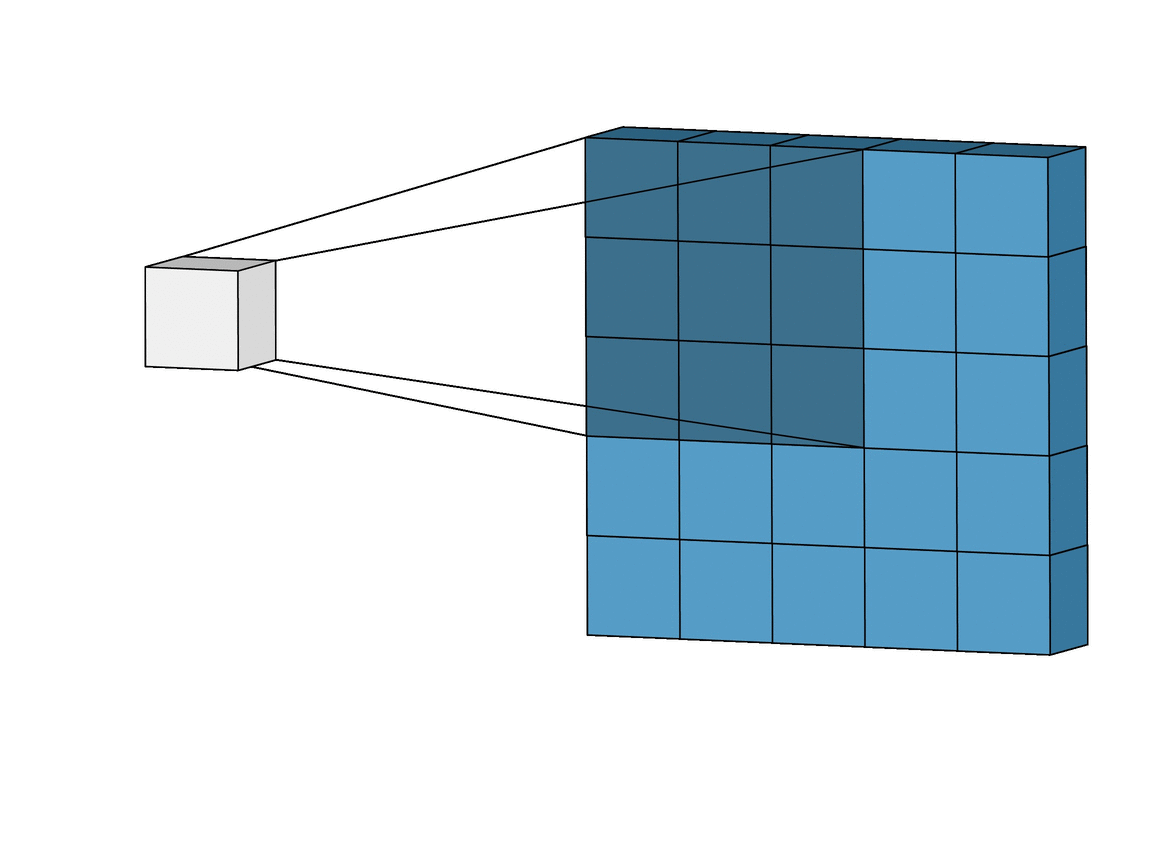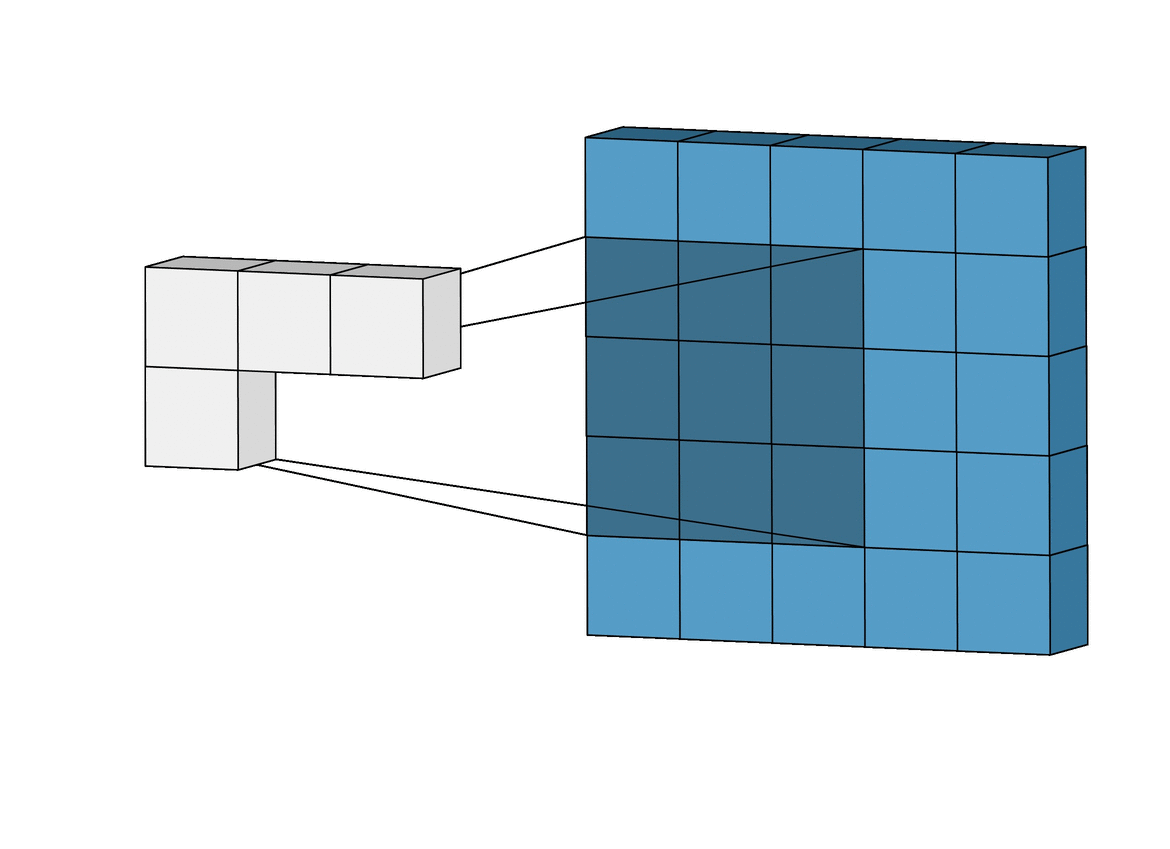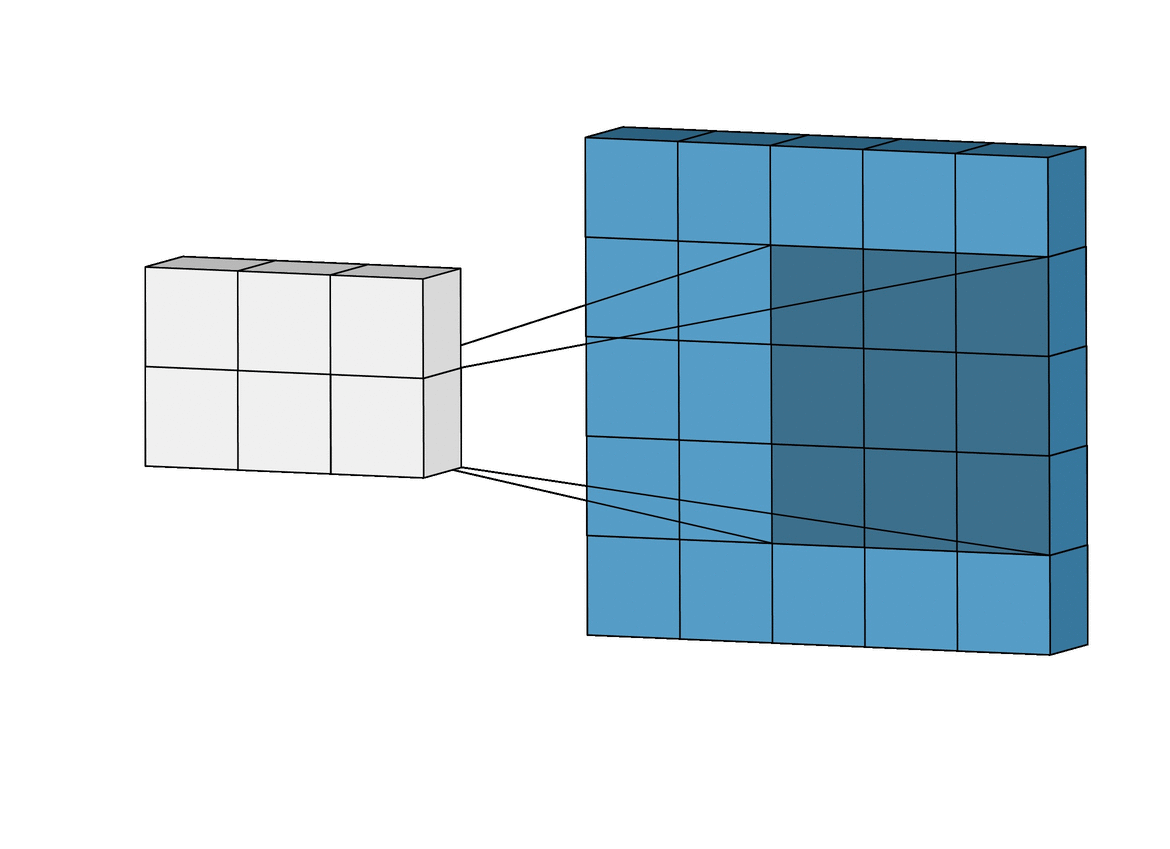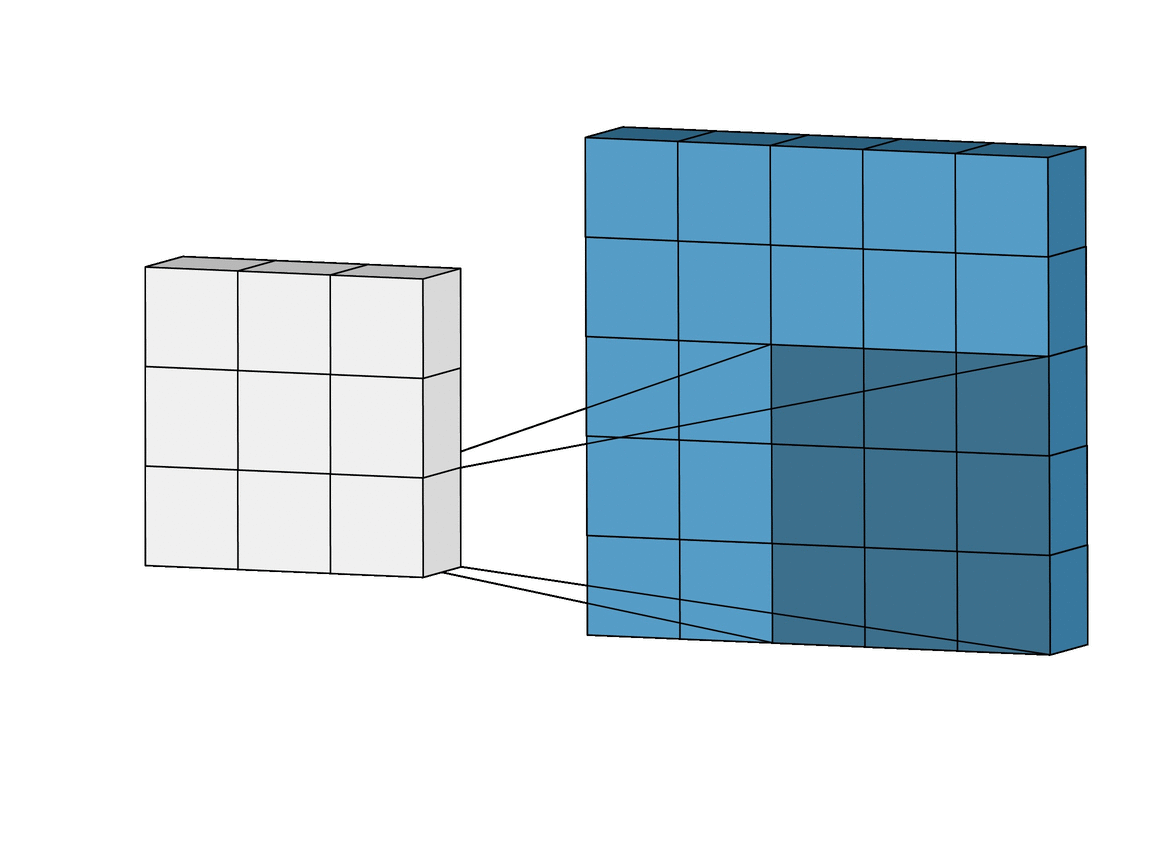
I'm trying to write a convolution function in C for my computer vision study. In this function, every pixel in the convolved image is a sum of product of original image and filter kernel like in this image and this gif.
{kind=link}
{kind=link}
In the code below pixel values are float. get_pixel() function gets the pixel value at given indexes. set_pixel() function sets the value to given indexes.
ANSWER
Answered 2020-Jul-22 at 12:55This is clearly an out of bounds access:
QUESTION
I have made a list called list and two doubles called Weight and Age
Then I tried getting an element from the list like this list.get((Age * 2) - 1), but it told me I can't put a double in the get() function, so I tried doing this (int)(Age-1) but when I put that chunk of code in an if() command like so
if(list.get((int) ((Age * 2) - 1)) > Weight.intValue())
but then for some reason, it gives me this exeption:
operator ">" cannot be applied to "java.lang.Object","int"
WHY, JUST WHY!
in total, here is my code (Note that I wrote it with some extra android libraries)
...ANSWER
Answered 2020-Jul-18 at 00:20you use not generic list.
QUESTION
Well, I'm doing an app in android. I have a listView to show data of my Firebase, this listView have rows with textView and delete button, when I want to delete a certain data, I click in the delete button but appears this error java.lang.NullPointerException: Attempt to invoke virtual method 'void android.widget.TextView.setText(java.lang.CharSequence)' on a null object reference
CustomAdapterData.java
...ANSWER
Answered 2020-Jul-11 at 04:15You are creating data object in onclick which is throwing null pointer. I havent Changed your code much so that you get idea about what has changed in code, but you need to initialize those views inside if .
QUESTION
I recently found my linux test server /var/log/ is full, it has used 3.8g. But when I list the files in it, it only shows around 800M.
df -hl
...ANSWER
Answered 2020-Jul-01 at 07:24Use
du -h /var/logorls -hal -R /var/logto show all. On Linux, i.e. Raspberry Pi, i using a simple softlink for unwanted spam logs. The target is like a black hole and eats everything...
ln -sf /dev/null /var/log/anaconda.log
And of course you have to do this as super Q user root
QUESTION
{kind=link}
ANSWER
Answered 2020-Jun-30 at 13:00Except for the fact, that we do not see your code, I strongly doubt, that this setup is going to work the way you intended.
Assuming this is USB 2.x the signal lines (white) will have a voltage level of 0V to 400 mV, while the power line (red) operates at 5V against GND(black). I strongly doubt, that this is within the specs of your relay.
Even if it is, you can not easily steer one of the signal lines from operating system level as you need some abstraction layer in between. The normal OS drivers can not work with your setup as they expect a controller at the other end of the line doing USB standard compliant stuff like enumeration, speed and current settings, etc. For your OS this is just a cut off line plugged into USB port.
The approach your looking for might be the following:
A OS application on your PC is connected to a microcontroller via USB or Serial-USB-Adapter. The Microcontroller recieves simple commands via this connection and in turn sets and resets his I/O pins. Those I/O pins are level-driven and fed into your relay. Depending on your relay you need some amplification in between the microcontroller and the relay.
If you're really sure your hardware setup can work, please include a detailed description, including electrical levels, used USB port, datasheet of the relay and the code you're trying to run.
Community Discussions, Code Snippets contain sources that include Stack Exchange Network
Vulnerabilities
No vulnerabilities reported
Install imc
You can use imc like any standard Java library. Please include the the jar files in your classpath. You can also use any IDE and you can run and debug the imc component as you would do with any other Java program. Best practice is to use a build tool that supports dependency management such as Maven or Gradle. For Maven installation, please refer maven.apache.org. For Gradle installation, please refer gradle.org .
Support
Reuse Trending Solutions
Find, review, and download reusable Libraries, Code Snippets, Cloud APIs from over 650 million Knowledge Items
Find more librariesStay Updated
Subscribe to our newsletter for trending solutions and developer bootcamps
Share this Page