readr | Readr is a minimal responsive WP theme | Content Management System library
kandi X-RAY | readr Summary
kandi X-RAY | readr Summary
Readr is a minimal responsive WP theme that focuses on content.
 Support
Support
 Quality
Quality
 Security
Security
 License
License
 Reuse
Reuse
Top functions reviewed by kandi - BETA
- Register readr options .
readr Key Features
readr Examples and Code Snippets
Community Discussions
Trending Discussions on readr
QUESTION
So I was really ripping my hair out why two different sessions of R with the same data were producing wildly different times to complete the same task.
After a lot of restarting R, cleaning out all my variables, and really running a clean R, I found the issue: the new data structure provided by vroom and readr is, for some reason, super sluggish on my script. Of course the easiest thing to solve this is to convert your data into a tibble as soon as you load it in. Or is there some other explanation, like poor coding praxis in my functions that can explain the sluggish behavior? Or, is this a bug with recent updates of these packages? If so and if someone is more experienced with reporting bugs to tidyverse, then here is a repex showing the behavior cause I feel that this is out of my ballpark.
ANSWER
Answered 2021-Jun-15 at 14:37This is the issue I had in mind. These problems have been known to happen with vroom, rather than with the spec_tbl_df class, which does not really do much.
vroom does all sorts of things to try and speed reading up; AFAIK mostly by lazy reading. That's how you get all those different components when comparing the two datasets.
With vroom:
QUESTION
I am trying to follow this tutorial here - https://juliasilge.com/blog/xgboost-tune-volleyball/
I am using it on the most recent Tidy Tuesday dataset about great lakes fishing - trying to predict agency based on many other values.
ALL of the code below works except the final row where I get the following error:
...ANSWER
Answered 2021-Jun-15 at 04:08If we look at the documentation of last_fit() We see that split must be
An rsplit object created from `rsample::initial_split().
You accidentally passed the cross-validation folds object stock_folds into split but you should have passed rsplit object stock_split instead
QUESTION
Edit: It looks like this is a known issue with the "cascade" method. Results that return NA values after the first attempt don't like being converted to doubles when subsequent methods return lat/lons.
Data: I have a list of addresses that I need to geocode. I'm using lapply() to split-apply-combine, which works, but very slowly. My thought to split (further)-apply-combine is returning errors about dim names and sizes that are confusing to me.
ANSWER
Answered 2021-Jun-14 at 15:59It is working with dplyr 1.0.6
QUESTION
I just noticed that read_csv() somehow uses random numbers which is unexpected (at least to me). The corresponding base R function read.csv() does not do that. So, what does read_csv() use the random numbers for? I looked into the documentation but could not find a clear answer to that. Are the random numbers related to the guess_max argument?
ANSWER
Answered 2021-Jun-10 at 19:21tl;dr somewhere deep in the guts of the cli package (called to generate the pretty-printed output about column types), the code is generating a random string to use as a label.
A major clue is that
QUESTION
How can I convert my column "payment" from long to wide format while keeping the other columns unchanged?
For each level of "letter", when the cell is before the value of "payment", then when in the wide format this row of the corresponding new variable "e.g., dollar" will have "0"; otherwise "1".
I tried output_format_test<-input_format%>%tidyr::pivot_wider(names_from = age, values_from = payment), but it does not produce the intended result.
##Input format
...ANSWER
Answered 2021-Jun-04 at 14:30Tidyverse approach
QUESTION
I am looping to load multiple xlsx files. This I am doing well. But when I want to add the name of the columns of the documents (the same names for all files) I have not managed to do it.
...ANSWER
Answered 2021-Jun-03 at 07:45I cannot check this since I don't have Excel files to load, but I think this should work:
QUESTION
I'm trying to come up with a neat/fast way to read files delimited by newline (\n) characters into more than one column.
Essentially in a given input file, multiple rows in the input file should become a single row in the output, however most file reading functions sensibly interpret the newline character as signifying a new row, and so they end up as a data frame with a single column. Here's an example:
The input files look like this:
...ANSWER
Answered 2021-Apr-12 at 14:59You can get round some of the string manipulation with something along the lines of:
QUESTION
Here is 1 row of data we are fetching from a sports API that comes into us as a nested list. Our fetch_results$data is a list with a nested lists like this for each of many games, as this data is for many soccer matches. The list-of-list nesting can go 3-4 layers deep, with inner lists for scores, and time, and visitorTeam below, and more.
ANSWER
Answered 2021-May-30 at 02:57An option is to convert to NA before we do anything. This can be done in a recursive way with rrapply
QUESTION
I am working with the current tidytuesday data about salaries and trying to create a model with tidymodels and recipes. I want to predict salary with many of the other factors present using the recipes code, but I run into an issue.
Issue 1 - My recipe says there are empty rows, but I do not know how to figure out how. This does not give an error, so maybe it is not a problem.
Issue 2 - Understanding what my models actually did and how to visualize the performance. I want to plot the models performance on the initial data. Here is an example of my goal: https://indescribled.files.wordpress.com/2021/05/image-17.png?w=782
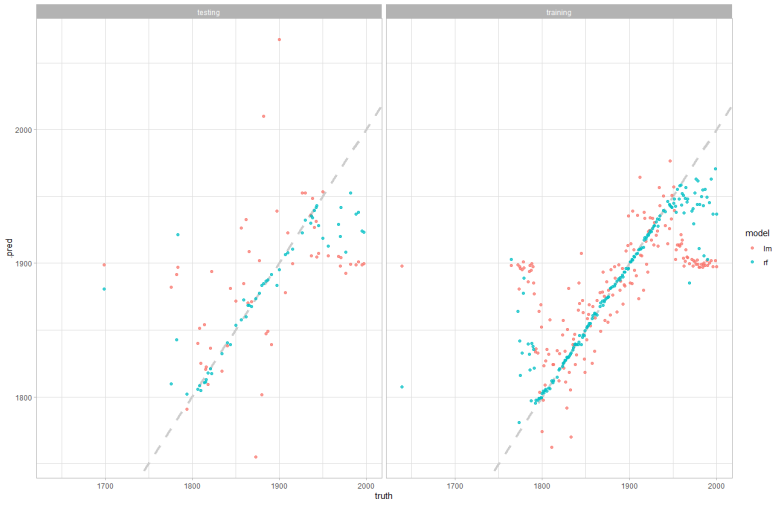{kind=link}
I do not understand exactly how to use the predict function with my recipe. juice(rec) is less than 1000 rows while the testing data is about 6000. Perhaps I am reading it backwards, but can someone try to point me in the right direction?
The code below should be an exact reproduction of mine.
...ANSWER
Answered 2021-May-24 at 23:31Looks like you have things pretty well along!
QUESTION
I am able to read in a subset of columns defined in cols_only like so:
ANSWER
Answered 2021-May-21 at 19:30If the splicing is not working, use do.call
Community Discussions, Code Snippets contain sources that include Stack Exchange Network
Vulnerabilities
No vulnerabilities reported
Install readr
PHP requires the Visual C runtime (CRT). The Microsoft Visual C++ Redistributable for Visual Studio 2019 is suitable for all these PHP versions, see visualstudio.microsoft.com. You MUST download the x86 CRT for PHP x86 builds and the x64 CRT for PHP x64 builds. The CRT installer supports the /quiet and /norestart command-line switches, so you can also script it.
Support
Reuse Trending Solutions
Find, review, and download reusable Libraries, Code Snippets, Cloud APIs from over 650 million Knowledge Items
Find more librariesStay Updated
Subscribe to our newsletter for trending solutions and developer bootcamps
Share this Page