speculatively | Package speculatively provides a simple mechanism | Architecture library
kandi X-RAY | speculatively Summary
kandi X-RAY | speculatively Summary
Package speculatively provides a simple mechanism to speculatively execute a task in parallel only after some initial timeout has elapsed:.
 Support
Support
 Quality
Quality
 Security
Security
 License
License
 Reuse
Reuse
Top functions reviewed by kandi - BETA
Currently covering the most popular Java, JavaScript and Python libraries. See a Sample of speculatively
speculatively Key Features
speculatively Examples and Code Snippets
Community Discussions
Trending Discussions on speculatively
QUESTION
I'm facing problem that is really strange for me.
I'm trying to use Flutter's DataTable widget. It works with hardcoded mockup data, but as soon as I try it with real data, I get exceptions.
...ANSWER
Answered 2021-May-23 at 17:46Inside DataTable - When you are using Text widget inside DataCell, use isIntrinsic prop along with your text. For eg - e.value.toString().text.isIntrinsic.make(). Let me know if it doesn’t work.
QUESTION
As I understand, when a CPU speculatively executes a piece of code, it "backs up" the register state before switching to the speculative branch, so that if the prediction turns out wrong (rendering the branch useless) -- the register state would be safely restored, without damaging the "state".
So, my question is: can a speculatively executed CPU branch contain opcodes that access RAM?
I mean, accessing the RAM isn't an "atomic" operation - one simple opcode reading from memory can cause actual RAM access, if the data isn't currently located in the CPU cache, which might turn out as an extremely time consuming operation, from the CPU perspective.
And if such access is indeed allowed in a speculative branch, is it only for read operations? Because, I can only assume that reverting a write operation, depending on it's size, might turn out extremely slow and tricky if a branch is discarded and a "rollback" is performed. And, for sure, read/write operations are supported, to some extent at least, due to the fact that the registers themselves, on some CPUs, are physically located on the CPU cache as I understand.
So, maybe a more precise formulation would be: what are the limitations of a speculatively executed piece of code?
...ANSWER
Answered 2020-Oct-12 at 13:25The cardinal rules of speculative out-of-order (OoO) execution are:
- Preserve the illusion of instructions running sequentially, in program order
- Make sure speculation is contained to things that can be rolled back if mis-speculation is detected, and that can't be observed by other cores to be holding a wrong value. Physical registers, the back-end itself that tracks instruction order yes, but not cache. Cache is coherent with other cores so stores must not commit to cache until after they're non-speculative.
OoO exec is normally implemented by treating everything as speculative until retirement. Every load or store could fault, every FP instruction could raise an FP exception. Branches are special (compared to exceptions) only in that branch mispredicts are not rare, so a special mechanism to handle early detection and roll-back for branch misses is helpful.
Yes, cacheable loads can be executed speculatively and OoO because they have no side effects.
Store instructions can also be executed speculatively thanks to the store buffer. The actual execution of a store just writes the address and data into the store buffer. (related: Size of store buffers on Intel hardware? What exactly is a store buffer? gets more techincal than this, with more x86 focus. This answer is I think applicable to most ISAs.)
Commit to L1d cache happens some time after the store instruction retires from the ROB, i.e. when the store is known to be non-speculative, the associated store-buffer entry "graduates" and becomes eligible to commit to cache and become globally visible. A store buffer decouples execution from anything other cores can see, and also insulates this core from cache-miss stores so it's a very useful feature even on in-order CPUs.
Before a store-buffer entry "graduates", it can just be discarded along with the ROB entry that points to it, when rolling back on mis-speculation.
(This is why even strongly-ordered hardware memory models still allow StoreLoad reordering https://preshing.com/20120930/weak-vs-strong-memory-models/ - it's nearly essential for good performance not to make later loads wait for earlier stores to actually commit.)
The store buffer is effectively a circular buffer: entries allocated by the front-end (during alloc/rename pipeline stage(s)) and released upon commit of the store to L1d cache. (Which is kept coherent with other cores via MESI).
Strongly-ordered memory models like x86 can be implemented by doing commit from the store buffer to L1d in order. Entries were allocated in program order, so the store buffer can basically be a circular buffer in hardware. Weakly-ordered ISAs can look at younger entries if the head of the store buffer is for a cache line that isn't ready yet.
Some ISAs (especially weakly ordered) also do merging of store buffer entries to create a single 8-byte commit to L1d out of a pair of 32-bit stores, for example.
Reading cacheable memory regions is assumed to have no side effects and can be done speculatively by OoO exec, hardware prefetch, or whatever. Mis-speculation can "pollute" caches and waste some bandwidth by touching cache lines that the true path of execution wouldn't (and maybe even triggering speculative page-walks for TLB misses), but that's the only downside1.
MMIO regions (where reads do have side-effects, e.g. making a network card or SATA controller do something) need to be marked as uncacheable so the CPU knows that speculative reads from that physical address are not allowed. If you get this wrong, your system will be unstable - my answer there covers a lot of the same details you're asking about for speculative loads.
High performance CPUs have a load buffer with multiple entries to track in-flight loads, including ones that miss in L1d cache. (Allowing hit-under-miss and miss-under-miss even on in-order CPUs, stalling only if/when an instruction tries to read load-result register that isn't ready yet).
In an OoO exec CPU, it also allows OoO exec when one load address is ready before another. When data eventually arrives, instructions waiting for inputs from the load result become ready to run (if their other input was also ready). So the load buffer entries have to be wired up to the scheduler (called the reservation station in some CPUs).
See also About the RIDL vulnerabilities and the "replaying" of loads for more about how Intel CPUs specifically handle uops that are waiting by aggressively trying to start them on the cycle when data might be arriving from L2 for an L2 hit.
Footnote 1: This downside, combined with a timing side-channel for detecting / reading micro-architectural state (cache line hot or cold) into architectural state (register value) is what enables Spectre. (https://en.wikipedia.org/wiki/Spectre_(security_vulnerability)#Mechanism)
Understanding Meltdown as well is very useful for understanding the details of how Intel CPUs choose to handle fault-suppression for speculative loads that turn out to be on the wrong path. http://blog.stuffedcow.net/2018/05/meltdown-microarchitecture/
And, for sure, read/write operations are supported
Yes, by decoding them to separate logically separate load / ALU / store operations, if you're talking about modern x86 that decodes to instructions uops. The load works like a normal load, the store puts the ALU result in the store buffer. All 3 of the operation can be scheduled normally by the out-of-order back end, just like if you'd written separate instructions.
If you mean atomic RMW, then that can't really be speculative. Cache is globally visible (share requests can come at any time) and there's no way to roll it back (well, except whatever Intel does for transactional memory...). You must not ever put a wrong value in cache. See Can num++ be atomic for 'int num'? for more about how atomic RMWs are handled, especially on modern x86, by delaying response to share / invalidate requests for that line between the load and the store-commit.
However, that doesn't mean that lock add [rdi], eax serializes the whole pipeline: Are loads and stores the only instructions that gets reordered? shows that speculative OoO exec of other independent instructions can happen around an atomic RMW. (vs. what happens with an exec barrier like lfence that drains the ROB).
Many RISC ISAs only provide atomic RMW via load-linked / store-conditional instructions, not a single atomic RMW instruction.
[read/write ops ...], to some extent at least, due to the fact that the registers themselves, on some CPUs, are physically located on the CPU cache as I understand.
Huh? False premise, and that logic doesn't make sense. Cache has to be correct at all times because another core could ask you to share it at any moment. Unlike registers which are private to this core.
Register files are built out of SRAM like cache, but are separate. There are a few microcontrollers with SRAM memory (not cache) on board, and the registers are memory-mapped using the early bytes of that space. (e.g. AVR). But none of that seems at all relevant to out-of-order execution; cache lines that are caching memory are definitely not the same ones that are being used for something completely different, like holding register values.
It's also not really plausible that a high-performance CPU that's spending the transistor budget to do speculative execution at all would combine cache with register file; then they'd compete for read/write ports. One large cache with the sum total read and write ports is much more expensive (area and power) than a tiny fast register file (many read/write ports) and a small (like 32kiB) L1d cache with a couple read ports and 1 write port. For the same reason we use split L1 caches, and have multi-level caches instead of just one big private cache per core in modern CPUs. Why is the size of L1 cache smaller than that of the L2 cache in most of the processors?
Related reading / background:
- https://stackoverflow.com/tags/x86/info has some good CPU-architecture links.
- https://www.realworldtech.com/haswell-cpu/5/ David Kanter's Haswell deep-dive.
- Size of store buffers on Intel hardware? What exactly is a store buffer?
- what is a store buffer?
- How do the store buffer and Line Fill Buffer interact with each other?
- Out-of-order execution vs. speculative execution - Everything is speculative until retirement. My answer there focuses on the Meltdown aspect.
- http://blog.stuffedcow.net/2018/05/meltdown-microarchitecture/
- What exactly happens when a skylake CPU mispredicts a branch?
- https://en.wikipedia.org/wiki/MESI_protocol#Store_Buffer
- https://en.wikipedia.org/wiki/Write_buffer (not a great article, but mentioned for completeness).
- How does memory reordering help processors and compilers? (StoreLoad reordering allows for a store buffer and is essentially necessary for good performance.)
- https://en.wikipedia.org/wiki/Memory_disambiguation - how the CPU handles forwarding from the store buffer to a load, or not if the store was actually younger (later in program order) than this load.
- https://blog.stuffedcow.net/2014/01/x86-memory-disambiguation/ - Store-to-Load Forwarding and Memory Disambiguation in x86 Processors. Very detailed test results and technical discussion of store-forwarding, including from narrow loads that overlap with different parts of a store, and near cache-line boundaries. (https://agner.org/optimize/ has some simpler-to-understand but less detailed info about when store-forwarding is slow vs. fast in his microarch PDF.)
- Globally Invisible load instructions - store forwarding from loads that partially overlap a recent store and partially don't gives us a corner case that sheds some light on how CPUs work, and how it does/doesn't make sense to think about memory (ordering) models. Note that C++ std::atomic can't create code that does this, although C++20 std::atomic_ref could let you do an aligned 4-byte atomic store that overlaps an aligned 8-byte atomic load.
QUESTION
I'm writing a PIN tool where I want to see speculatively executed instructions that were eventually squashed.
I.e. if a branch direction was predicted, some instructions were executed speculatively, the branch direction was resolved and the prediction was shown to be incorrect, the instructions that were executed would then be squashed and the register file would be restored.
I assume that RTN_AddInstrumentFunction only adds an instrument function to instructions that were retired (i.e. non-speculative or speculative and shown to be correct). Is there a way for me to use PIN to get access to instructions that were executed speculatively but then squashed?
ANSWER
Answered 2020-May-21 at 04:12You can't do that with binary instrumentation tools like PIN, only with hardware performance counters.
PIN can only see instructions along the correct path of execution; it works by adding / modifying instructions in memory to run extra code. But this new code is still just x86 machine code that the CPU has to execute, giving the illusion of running each instruction one at a time, in program order.
Mis-speculated instructions have no architectural effect so only stuff with special access to the micro-architectural state (like performance counters) can tell you anything about them.
There are perf counters for mispredicts, like perf stat -e branch-misses to count number of branches that were mis-predicted.
Number of bad uops issued by the front-end in the shadow of a mis-speculation that have to be cancelled can be derived (on Skylake and probably other Intel) from
uops_issued.any - uops_retired.retire_slots. Both count fused-domain uops and match each other ~exactly when there's no mis-speculation of any kind (branches, memory-order mis-speculation pipelien nukes, or whatever else).
QUESTION
I've recently been looking into a concept for a CPU architecture called the Mill.
The Mill (though it may be vaporware) uses metadata for various things in the CPU, such as a software speculative load producing a value tagged as not a result (NaR). If a later instruction tries to store that result non-speculatively, hardware detects that and faults.
I was wondering if any other CPU's are similar in the sense of using metadata in the architecture.
...ANSWER
Answered 2020-May-11 at 17:04A few random examples I know of, certainly not an exhaustive list. IDK if there are any that use metadata for all the things the Mill does. Some of what the Mill does is unique, but some of the ideas have appeared in similar forms in other ISAs.
Yes, IA-64 Itanium also had not-a-thing load results that would fault if you read them, for the same software-speculation reason as the Mill. Its architects described it as an EPIC ISA. (EPIC = Explicitly Parallel Instruction Computing, as opposed to CISC or RISC. It's also a VLIW.) From Wikipedia:
The architecture implements a large number of registers:
128 general integer registers, which are 64-bit plus one trap bit ("NaT", which stands for "not a thing") used for speculative execution. 32 of these are static, the other 96 are stacked using variably-sized register windows, or rotating for pipelined loops. gr0 always reads 0.
128 floating point registers. The floating point registers are 82 bits long to preserve precision for intermediate results. Instead of a dedicated "NaT" trap bit like the integer registers, floating point registers have a trap value called "NaTVal" ("Not a Thing Value"), similar to (but distinct from) NaN. These also have 32 static registers and 96 windowed or rotating registers. fr0 always reads +0.0, and fr1 always reads +1.0.
So for integer, there truly is separate metadata. For FP, the metadata is encoded in-band.
Other examples of metadata that aren't related to software-visible speculation include:
The x87 FPU has 8 architectural registers, but normal instructions access them as a register stack where the underlying register for st(0) is determined by a field in the x87 status word. (i.e. the metadata is architecturally visible and can be modified with fincstp to rotate the "revolver barrel".) See http://www.ray.masmcode.com/tutorial/fpuchap1.htm for a good diagram and intro to the x87 design. Also, x87 has a free / in-use flag for each register; trying to load into an already in use register produces an FP exception (and a NaN if exceptions are masked). Normally the in-use flag is cleared by "popping" the register stack with fstp to store and pop, or whatever, but there's also ffree to mark any x87 register as free.
Obviously a microarchitecture has to keep lots of info about instructions that are in flight, like whether they've finished executing or not. But there is at least one interesting case of metadata about data, not code:
In AMD Bulldozer-family and Bobcat/Jaguar, the SIMD FPUs apparently keep some extra metadata alongside the actual architectural register value. As Agner Fog explains in his microarchitecture PDF, (Bulldozer-family) 19.11 Data delay between different execution domains:
There is a large penalty when the output of a floating point calculation is input to a floating point calculation with a different precision, for example if the output of a double precision floating point addition is input to a single precision addition. This has hardly any practical significance since such a sequence is most likely to be a programming error, but it indicates that the processor stores extra information about floating point numbers beyond the 128 bits in an XMM register. This effect is not seen on Intel processors.
This might possibly be related to the fact that Bulldozer has FP latency 1 cycle lower when forwarding from an FMA-unit instruction to another FMA instruction, like mulps forwarding to addps with no sqrtps or xorps in between.
Also various AMD uarches have marked instruction boundaries in L1 I-cache, reducing / latency of decoding repeatedly. Intel Silvermont also does this.
QUESTION
I wonder which parallel strategy, spark, or whatever, can be used for speculative execution of a Haskell program that consists of a lot of conditional tests, recursively.
Assume a program that has a lot of conditional tests, recursively. I imagine that if sparks are used, then most sparks will be working on useless branches. The spark lifecycle does not include cancellation.
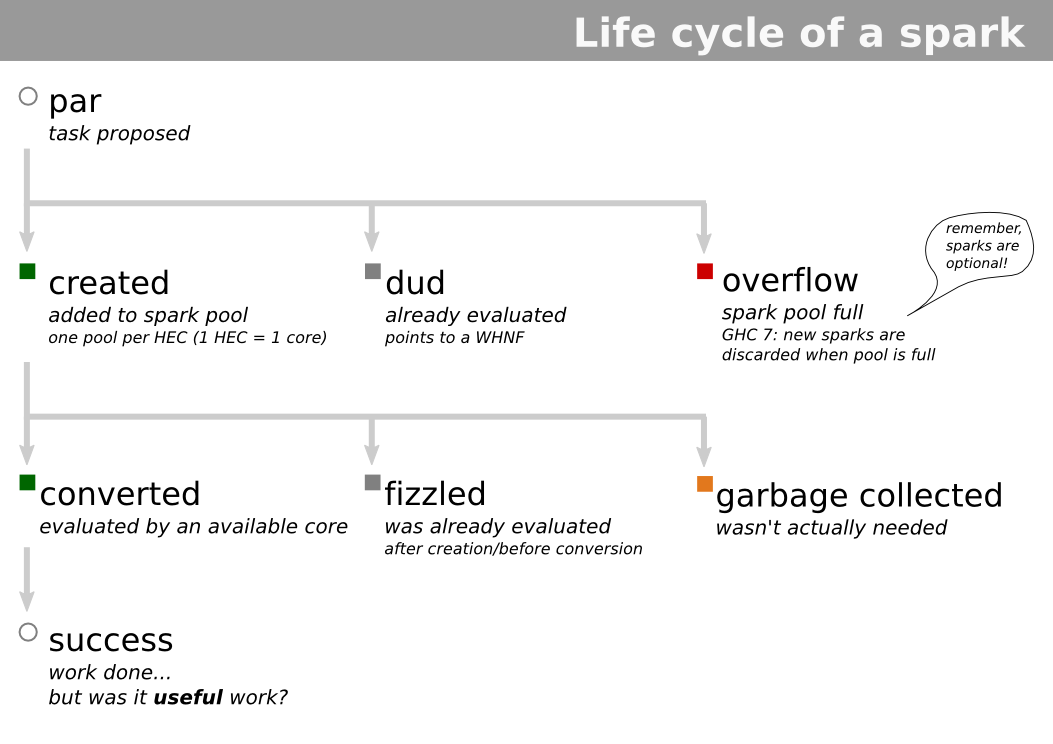{kind=link}
A workable strategy has to be able to efficiently create, but also cancel, units of work, in a dependency tree.
As an example, consider the problem of parsing a text. A parser consists of a huge tree of basically:
...ANSWER
Answered 2020-Feb-14 at 18:45If we can countenance abandoning the world of pure parallel computations, we can turn to the async package, which allows cancellation of asynchronous tasks.
For example, here's an speculative "if" that allows conditions that take a while to be calculated. It launches both branches concurrently, and when the result of the condition becomes known promptly kills the losing branch:
QUESTION
Alright, so I know that if a particular conditional branch has a condition that takes time to compute (memory access, for instance), the CPU assumes a condition result and speculatively executes along that path. However, what would happen if, along that path, yet another slow conditional branch pops up (assuming, of course, that the first condition hasn't been resolved yet and the CPU can't just commit the changes)? Does the CPU just speculate inside the speculation? What happens if the last condition is mispredicted but the first wasn't? Does it just rollback all the way?
I'm talking about something like this:
...ANSWER
Answered 2019-Dec-07 at 20:24Speculative execution is the regular state of execution, not a special mode that an out of order CPU enters when it sees a branch and then leaves when the branch is no longer in flight.
This is easier to see if you consider that it's not just branches that can fault, but many instructions, including those that access memory, have restrictions on their input values, etc. So any substantial out of order execution implies constant speculation, and CPUs are built around that idea.
So "nested branches" doesn't end up being special in that sense.
Now, modern CPUs have a variety of methods for quick branch misprediction recovery, faster than recovery from other types of faults1. For example they may snapshot the state of the register mapping at some branches, to allow recovery to start before the branch is at the head of the reorder buffer. Since it is not always feasible to snapshot at all branches, there might be complicated heuristics involved to decide where to take snapshots.
I mention this last part because it is one way in which nested branches might matter: when there are lots of branches in flight, you might hit some microarchitectural limits related to the tracking of these branches for recovery purposes. For more details, you can look through patents for "branch order buffer" (for Intel techniques, but there are no doubt others).
1 The basic recovery method is keep executing until the faulting instruction is the next to retire, and then throw away all younger instructions. In the context of branch mispredictions, this means you could actually suffer two or more mispredictions only the oldest of which actually takes effect: e.g., a younger branch mispredicts, and while executing up to that branch (at which point recovery can occur), another mispredict occurs, so the younger one ends up getting discarded.
QUESTION
std::atomic_uint64_t writing_ {0};
std::atomic_uint64_t reading_ {0};
std::array storage_ {};
bool try_enqueue(type t) noexcept
{
const std::uint64_t writing {
writing_.load(std::memory_order::memory_order_relaxed)};
const auto last_read {reading_.load(std::memory_order::memory_order_relaxed)};
if (writing - last_read < size) {
storage_.at(writing & (size - 1)) = t;
writing_.store(writing + 1, std::memory_order::memory_order_release);
return true;
}
else
return false;
}
ANSWER
Answered 2019-Sep-17 at 02:58Is it correct that an operation cannot be perceived as having occurred before a conditional it is sequenced after?
C++ compilers definitely aren't allowed to invent writes to atomic (or volatile) objects.
Compilers aren't even allowed to invent writes to non-atomic objects (e.g. turn a conditional write into read + cmov + write) because C++11 introduced a memory model that makes it well-defined for two threads to run code like that at the same time as long as at most one of them actually writes (and a read is sequenced after). But two non-atomic RMWs could step on each other so don't work "as-if" the C++ abstract machine was running the source code, so it's not an option for the compiler to emit asm that does that.
But if the compiler knows an object is always written, it can pretty much do whatever it wants because a legal program can't observe the difference: that would involve data-race UB.
A little more specifically, could the processor speculatively execute the write (when the condition will eventually evaluate to false), another thread observe the write as having occurred, and then the first thread discarding the speculative write?
No, speculation doesn't escape the core doing the speculation. Otherwise when mis-speculation is detected, all cores would have to roll back their state!
This is one of the primary reasons for store buffers existing: to decouple OoO speculative execution of stores from commit to L1d cache (which is when the store becomes globally visible to other cores). And to decouple execution from cache-miss stores which is useful even on in-order non-speculative CPUs.
Stores don't commit to L1d until after the store instruction has retired from the out-of-order core (i.e. is known to be non-speculative). Retired stores that haven't committed yet are sometimes called "graduated" to distinguish them from other store-buffer entries that could potentially be discarded if the core needs to roll back to retirement state.
This allows hardware speculative execution without inventing writes.
(see also Size of store buffers on Intel hardware? What exactly is a store buffer? for more details. Fun fact: some CPUs, specifically PowerPC, can do store-forwarding of graduated stores between SMT threads on the same physical core, making stores visible to some cores before they become globally visible. But only for graduated stores, otherwise possible mis-speculation could leak out.)
In C++, a std::mo_release store forces the compiler to use sufficient barriers or release-store instructions (e.g. a normal mov on x86 is a release-store, or stlr on AArch64 is a sequential-release store). Or whatever other mechanism to make sure the asm guarantees runtime ordering at least as strong as the C++ abstract machine guarantees.
C++ defines its standard in terms of sequenced-before / after, not barriers, but on any given platform implementations / the ABI standardize on some mapping from std::atomic operations to asm sequences. (e.g. https://www.cl.cam.ac.uk/~pes20/cpp/cpp0xmappings.html)
QUESTION
I'm trying to run a Spark ML pipeline (load some data from JDBC, run some transformers, train a model) on my Yarn cluster but each time I run it, a couple - sometimes one, sometimes 3 or 4 - of my executors get stuck running their first task set (that'd be 3 tasks for each of their 3 cores), while the rest run normally, checking off 3 at a time.
In the UI, you'd see something like this:
{kind=link}
Some things I have observed so far:
- When I set up my executors to use 1 core each with
spark.executor.cores(i.e. run 1 task at a time), the issue does not occur; - The stuck executors always seem to be them ones that had to get some partitions shuffled to them in order to run the task;
- The stuck tasks would ultimately get successfully speculatively executed by another instance;
- Occasionally, a single task would get stuck in an executor that is otherwise normal, the other 2 cores would keep working fine, however;
- The stuck executor instances look like everything is normal: CPU is at ~100%, plenty of memory to spare, the JVM processes are alive, neither Spark or Yarn log anything out of the ordinary and they can still receive instructions from the driver, such as "drop this task, someone else speculatively executed it already" -- though, for some reason, they don't drop it;
- Those executors never get killed off by the driver, so I imagine they keep sending their heartbeats just fine;
Any ideas as to what may be causing this or what I should try?
...ANSWER
Answered 2019-Aug-02 at 00:16TLDR: Make sure your code is threadsafe and race condition-free before you blame Spark.
Figured it out. For posterity: was using an thread-unsafe data structure (a mutable HashMap). Since executors on the same machine share a JVM, this was resulting in data races that were locking up the separate threads/tasks.
The upshot: when you have spark.executor.cores > 1 (and you probably should), make sure your code is threadsafe.
QUESTION
I found the description of a speculative data caching procedure from multiple instruction entries in Intel Vol.2.
For example, the lfence:
Processors are free to fetch and cache data speculatively from regions of system memory that use the WB, WC, and WT memory types. This speculative fetching can occur at any time and is not tied to instruction execution. Thus, it is not ordered with respect to executions of the LFENCE instruction; data can be brought into the caches speculatively just before, during, or after the execution of an LFENCE instruction.
Also, I found from online resources that the speculative caching will move data from farther cache to closer cache as well.
I want to know whether the strongest serializing instruction CPUID will prevent speculative caching across the barrier.
I've already searched the CPUID entry in Intel Vol.2 and the "serializing instruction" section in Intel Vol.3. But it shows nothing about speculative data caching.
ANSWER
Answered 2019-Jul-10 at 04:33LFENCE is already strong enough (in practice at least) to stop the CPU from actually looking at load instructions after it, but the CPU is free to speculatively load for other reasons.
Stopping that would require some kind of lookahead past the barrier to find out what addresses to disable HW prefetch for. That's not practical at all. CPUID or other serializing instructions aren't any stronger than LFENCE for stopping load prefetches.
The CPU is always allowed to speculatively fetch from memory in WB and WT regions / pages. Intel's optimization manual documents some stuff about the hardware prefetchers in some of their CPU models, so you could in practice avoid doing things before CPUID that are likely to trigger such prefetches.
(WC is weakly-ordered uncacheable+write-combining, but speculative fetch is also allowed there on paper. In real life that probably only happens in the shadow of a branch mispredict, not HW prefetch. It's not normally cacheable like WB and WT.)
If you're microbenchmarking a real CPU, the trick to some kinds of microbenchmarks is to find an access pattern that won't trigger HW prefetching, or to disable the HW prefetchers.
Maybe in theory you could have an x86 CPU that looked ahead in the instruction stream for load/store instructions and speculatively prefetched for them, separate from actually executing them (which Intel's definition of LFENCE would block). I don't think anything would stop it from doing that across CPUID either.
Probably nobody will design such a CPU, because
- It's not worth the transistors / power. Starting prefetch as soon as regular out-of-order execution can get to it is already good enough. And except for absolute / RIP-relative addresses or direct jumps, you'd need register values from the OoO core to get a useful prefetch address.
- Looking past LFENCE / CPUID is perverse; they're rare enough that defeating speculative "execution" of loads past them is part of the point, in the age of Spectre.
QUESTION
I have an object of 64 byte in size:
...ANSWER
Answered 2019-May-14 at 01:44Regarding the case with store operations, I have run the same loop on a Haswell processor in four different configurations:
- MFENCE + E: There is an
MFENCEinstruction after the store. All hardware prefetchers are enabled. - E : There is no
MFENCE. All hardware prefetchers are enabled. - MFENCE + D: There is an
MFENCEinstruction after the store. All hardware prefetchers are disabled. - D : There is no
MFENCE. All hardware prefetchers are disabled.
The results are shown below, which are normalized by the number of stores (each store is to a different cache line). They are very deterministic across multiple runs.
Community Discussions, Code Snippets contain sources that include Stack Exchange Network
Vulnerabilities
No vulnerabilities reported
Install speculatively
Support
Reuse Trending Solutions
Find, review, and download reusable Libraries, Code Snippets, Cloud APIs from over 650 million Knowledge Items
Find more librariesStay Updated
Subscribe to our newsletter for trending solutions and developer bootcamps
Share this Page