microservice | microservice with springcloud and docker | Microservice library
kandi X-RAY | microservice Summary
kandi X-RAY | microservice Summary
microservice with springcloud and docker
 Support
Support
 Quality
Quality
 Security
Security
 License
License
 Reuse
Reuse
Top functions reviewed by kandi - BETA
- Check all external services .
- Register a service .
- Increase counter .
- region ServletHandlerRegistry
- Run the verification thread .
- Factory method for creating HelloService .
- Gets the HELLO message .
- Verify that the service is up .
- Handles a multipart upload request .
- Returns an error message
microservice Key Features
microservice Examples and Code Snippets
curl https://start.spring.io/starter.tgz -d dependencies=web -d baseDir=simple-microservice -d bootVersion=2.7.0 -d javaVersion=17 | tar -xzvf -
curl https://start.spring.io/starter.tgz -d dependencies=web,cloud-eureka,cloud-config-client -d baseDir=spring-cloud-microservice -d bootVersion=2.7.0 -d javaVersion=17 | tar -xzvf -
curl https://start.spring.io/starter.tgz -d dependencies=webflux,cloud-eureka,cloud-config-client -d baseDir=city-service -d bootVersion=2.7.0 -d javaVersion=17 | tar -xzvf -
Community Discussions
Trending Discussions on microservice
QUESTION
I have bunch of GRPC microservices and they are using self signed certs. I add authentication info to the GRPC channel which is then used to identify endpoints and provide right services.
Now I want migrate to Istio mTLS.
In phase one, I got Istio to BYPASS all GRPC connections and my services works as it is now.
In Phase two, I want to hand off TLS to Istio, but I am stuck on how to pass the authentication information to GRPC?
How do you handle auth in Istio mTLS setup?
GRPC can support other authentication mechanisms Has anyone used this to inject Istio auth info to GRPC? any other suggestions on how you implemented this in your setup
I am using go-lang just in case if this can be useful to provide any additional information.
Thanks
...ANSWER
Answered 2021-Jun-11 at 09:21One way of doing this is using grpc.WithInsecure(), this way you don't have to add certificates to your services, since istio-proxy containers in your pods will TLS terminate any incoming connections.
Client side:
QUESTION
let's assume this is my folder structure with all microservices and all package.json have start, dev and test scripts defined.
ANSWER
Answered 2021-Jun-15 at 10:54QUESTION
We have this Ansible inventory with dozens of servers, being grouped in servers per microservice. So say we have several application groups in the inventory with servers in it.
Say:
...ANSWER
Answered 2021-Jun-08 at 15:26there is already an answer on how to run playbooks on multiple hosts answered here Ansible: deploy on multiple hosts in the same time
Maybe you could start form there. However if running only first servers in parallel interests you than it will be more difficult, as it would require writing a custom script or something similar
QUESTION
I was following this tutorial https://kubernetes.io/docs/tutorials/configuration/configure-java-microservice/configure-java-microservice-interactive/
After packaging the mvn projects, I'm asked to deploy them by using the following YAML file with the following command
...ANSWER
Answered 2021-Jun-13 at 14:23If you type
QUESTION
Context:
- In Azure function with EventHubTrigger, I save data mapped from handled event to database (through the Entity framework). This action performs synchronously
- Trigger a new event about successful data insertion using event hub producer. This action is async
- Handle that triggered event at some other place
I guess it might happen that something fails during saving data, so I am wondering how to prevent inconsistency and secure that event is not sent if it should not. As far as I know Azure Event Hub has no outbox pattern implemented yet, so I guess I would need to mimic it somehow.
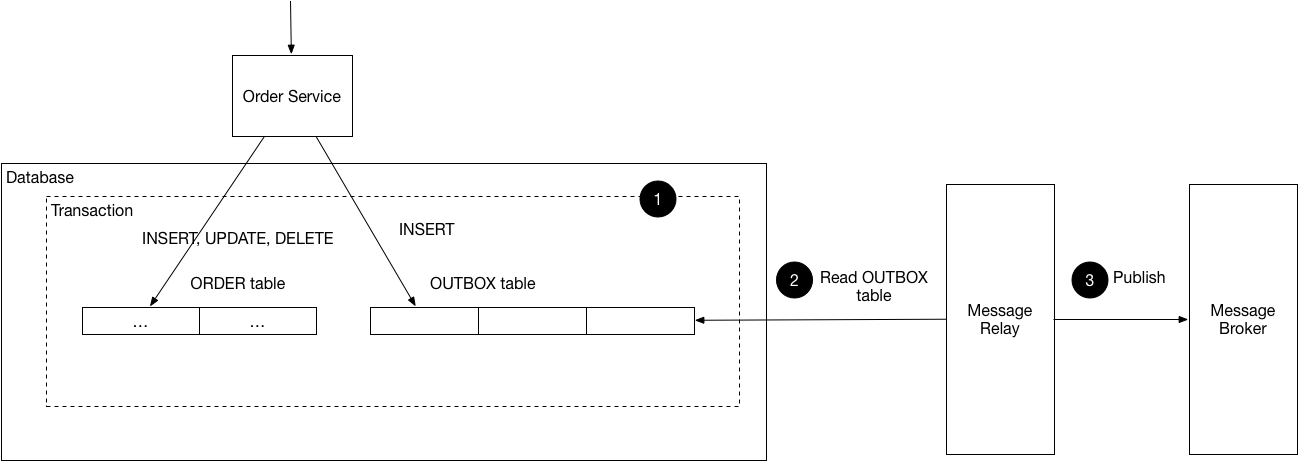{kind=link}
I am also thinking about alternative and a bit smelly solution to make this publish event method synchronous in step 2 (even if nature of the event-driven is to be async) and to add an addition check between step 1 and step 2 - to make sure that everything is saved in db. Only if that condition is fulfilled, event is going to be triggered (step 3).
Any advice?
...ANSWER
Answered 2021-Jun-11 at 19:52There's nothing in the SDK that would manage distributed transactions on your behalf. The simplest approach would likely be having a column in your database that allows you to mark when the event was published, and then have your function flow:
- Write to the database with the "event published" flag unset; on failure abort.
- Publish the event; on failure abort. (the data stays in written)
- Write to the database to set the "event published" flag.
You'd need a second Function running on a timer that could scan your database for rows older than XX minutes ago that still need an event, which then do steps 2 and 3 from your initial flow. In failure scenarios, you will have some potential latency between the data being written and the event published or may see duplicate events. (Event Hubs has an at least once guarantee, so you'll need to be able to handle duplicates regardless.)
QUESTION
I have defined a resource/method in API Gateway to make a post call to Lambda Function which is a microservice exposing few endpoints.
Method: post
Payload:
...ANSWER
Answered 2021-Jun-11 at 14:32But after analyzing and exploring several options I found that there was policy error "The final policy size (20577) is bigger than the limit (20480)". I removed the triggers & recreated, then it started to work.
QUESTION
I have 3 AWS Elastic Beanstalk instances which are running Spring microservices. All microservices are making POST requests to each other and using RDS service for database.
Should I isolate database traffic and microservices traffic into separate subnets? In case it's a good practice is it possible to assign 2 private network IP's for each subnet for every AWS Elastic Beanstalk instance?
...ANSWER
Answered 2021-Jun-09 at 01:46It's not a good practice to directly communicate between instances in EB. The reason is that that EB instances run in autoscalling group. So they can be terminated and replaced at any time by AWS leading to change in their private Ip addresses.
The change in IP will break your application sooner or later. Instances in EB should be accessed using Load Balancer or private IP.
So if you have some instances that are meant for private access only you could separate them to internal EB environment.
QUESTION
I have a Google VM running my dockerized application and i also have my Firebase front end application.
I want my Firebase application to trigger my microservice. The thing is, i want to be security conscious and i want the Firebase app to be the only actor who can trigger the microservice.
What is the best option for such a task? The only thing i have found are json web tokens (jwts). Is this good enough for the job? Is there something better?
If jwts are what is needed, then what is the logic that the code should have? Should the server create a key and send it to the microservice, then the microservice should decode it and only if it matches a value it should proceed with the job?
...ANSWER
Answered 2021-Jun-08 at 18:51firebaser here
The new Firebase App Check feature was made for this sort of thing, but how to access such app tokens from your own server-side code isn't decided yet.
So App Check currently allows specific Firebase services to only allow traffic from apps that are registered in the project. You are looking for the other side of that: only allow traffic from those apps to your services, which is not supported yet.
Also see https://groups.google.com/g/firebase-talk/c/rU0fEozdMyc/m/AYUa6PpLCAAJ
QUESTION
I want to get your opinion on a design decision. I need to prepare a project that makes the crud operations with weather sensors and I need the communicate each weather sensor with NTCIP in the database and get information like temperature, humidity, etc.
the problem is scaling. In my architecture, I write a .net core microservice and that has a own separate database. This weather station microservice reads all weather stations from the database then communicates each sensor via IP. I open a thread for each record and these threads do the data communication over IP. When I replicate this microservice, because of the same algorithm all microservice works with the same data. My goal is to distribute database data to replicated microservice by count. For example, if there are 100 weather station records in the database and I have 2 replicas I need to distribute 50 records to the first one, and 50 to the second one. Also, I need to if I change the replica count, the distribution will be redone. I search the internet, and I found a apache helix, but it's more complicated for this operation. Please give me advice. thanks a lot
...ANSWER
Answered 2021-Jun-09 at 12:16In .Net this sounds like a very good fit for Akka.Net. A reasonable "first cut" at a model would be to define an actor for each sensor and have these actors be sharded via cluster sharding, which will balance the number of sensor actors across the cluster and react to changes in cluster membership.
You might also find it useful to have the sensor actors be persistent via event sourcing, depending on where you want to go with this project (e.g. for publishing and archiving historical weather data).
QUESTION
I have a microservice written in Haskell, the compiler is 8.8.3.
I built it with --profile option and ran it with +RTS -p. It is running about 30 minutes, there is .prof file but it is empty (literally 0 bytes). Previously I did it on my local machine and I stop the service with CTRL-C and after the exit it produced .prof file which was not empty.
So, I have 2 questions:
- How to collect profiling information when a Haskell microservice runs under Kubernetes in the most correct way (to be able to read this .prof file)?
- How to pass run time parameter to Haskell run-time where to save this .prof file (maybe some workaround if no such an option), for 8.8.3 - because I have feeling that the file may be big and I can hit disk space problem. Also I don't know how to flush/read/get this file while microservice is running. I suppose if I will be able to pass full path for this .prof file then I can save it somewhere else on some permanent volume, to "kill" the service with
INTsignal for example, and to get this .prof file from the volume.
What is the usual/convenient way to get this .prof file when the service runs in Kubernetes?
PS. I saw some relevant options in the documentation for newest versions, but I am with 8.8.3
...ANSWER
Answered 2021-Jun-09 at 16:24I think the only way to do live profiling with GHC is to use the eventlog. You can insert Debug.Trace.traceEvent into your code at the functions that you want to measure and then compile with -eventlog and run with +RTS -l -ol -RTS. You can use ghc-events-analyze to analyze and visualize the produced eventlog.
The official eventlog documentation for GHC 8.8.3 is here.
Community Discussions, Code Snippets contain sources that include Stack Exchange Network
Vulnerabilities
No vulnerabilities reported
Install microservice
You can use microservice like any standard Java library. Please include the the jar files in your classpath. You can also use any IDE and you can run and debug the microservice component as you would do with any other Java program. Best practice is to use a build tool that supports dependency management such as Maven or Gradle. For Maven installation, please refer maven.apache.org. For Gradle installation, please refer gradle.org .
Support
Reuse Trending Solutions
Find, review, and download reusable Libraries, Code Snippets, Cloud APIs from over 650 million Knowledge Items
Find more librariesStay Updated
Subscribe to our newsletter for trending solutions and developer bootcamps
Share this Page