microservices | Microservice applications to show base architecture | Microservice library
kandi X-RAY | microservices Summary
kandi X-RAY | microservices Summary
Microservice applications to show base architecture
 Support
Support
 Quality
Quality
 Security
Security
 License
License
 Reuse
Reuse
Top functions reviewed by kandi - BETA
- Creates and returns a Joke exception with the given name
- Set the evil to be used
- Set the type of the response
- Sets the id
- Handles type mismatch
- Get the HTTP status
- Configure client details
- Configures this service
- Make Zipkin SpanReporter bean
- Gets the zipkin server
- Handle bind exception
- The Docket API
- Entry point
- Gets all team members
- Handles user request
- Handle HTTP media type not supported
- Handle HTTP method not supported
- Handle method argument not null
- H2 console
- Gets a request for a member
- Handle no handler exception
- Handle missing servlet request part
- Handle missing servlet request parameter
- Handle method argument type mismatch
- Handle all exceptions
- Handle ConstraintViolationException
microservices Key Features
microservices Examples and Code Snippets
Community Discussions
Trending Discussions on microservices
QUESTION
I have bunch of GRPC microservices and they are using self signed certs. I add authentication info to the GRPC channel which is then used to identify endpoints and provide right services.
Now I want migrate to Istio mTLS.
In phase one, I got Istio to BYPASS all GRPC connections and my services works as it is now.
In Phase two, I want to hand off TLS to Istio, but I am stuck on how to pass the authentication information to GRPC?
How do you handle auth in Istio mTLS setup?
GRPC can support other authentication mechanisms Has anyone used this to inject Istio auth info to GRPC? any other suggestions on how you implemented this in your setup
I am using go-lang just in case if this can be useful to provide any additional information.
Thanks
...ANSWER
Answered 2021-Jun-11 at 09:21One way of doing this is using grpc.WithInsecure(), this way you don't have to add certificates to your services, since istio-proxy containers in your pods will TLS terminate any incoming connections.
Client side:
QUESTION
let's assume this is my folder structure with all microservices and all package.json have start, dev and test scripts defined.
ANSWER
Answered 2021-Jun-15 at 10:54QUESTION
Context:
- In Azure function with EventHubTrigger, I save data mapped from handled event to database (through the Entity framework). This action performs synchronously
- Trigger a new event about successful data insertion using event hub producer. This action is async
- Handle that triggered event at some other place
I guess it might happen that something fails during saving data, so I am wondering how to prevent inconsistency and secure that event is not sent if it should not. As far as I know Azure Event Hub has no outbox pattern implemented yet, so I guess I would need to mimic it somehow.
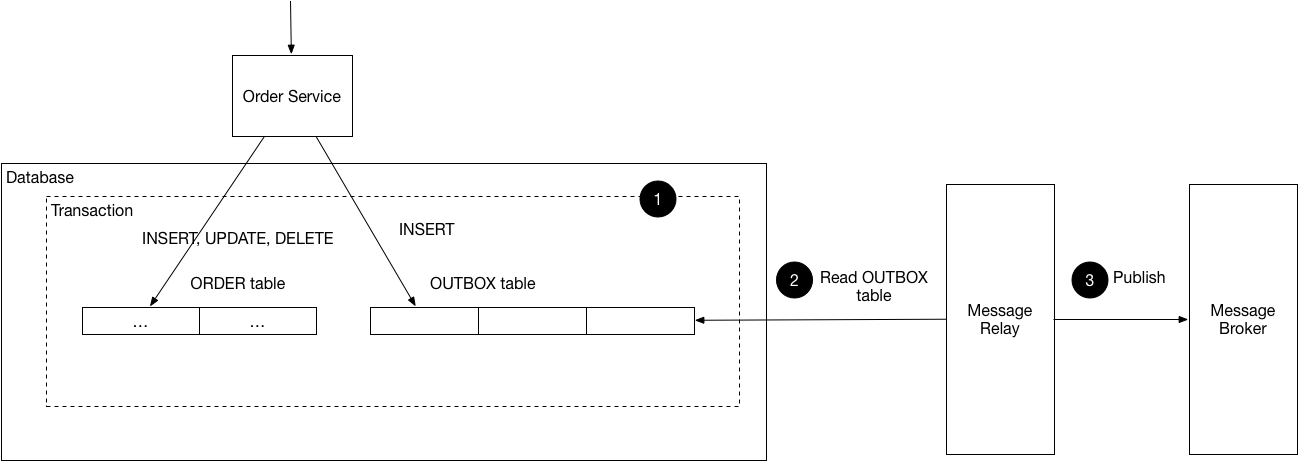{kind=link}
I am also thinking about alternative and a bit smelly solution to make this publish event method synchronous in step 2 (even if nature of the event-driven is to be async) and to add an addition check between step 1 and step 2 - to make sure that everything is saved in db. Only if that condition is fulfilled, event is going to be triggered (step 3).
Any advice?
...ANSWER
Answered 2021-Jun-11 at 19:52There's nothing in the SDK that would manage distributed transactions on your behalf. The simplest approach would likely be having a column in your database that allows you to mark when the event was published, and then have your function flow:
- Write to the database with the "event published" flag unset; on failure abort.
- Publish the event; on failure abort. (the data stays in written)
- Write to the database to set the "event published" flag.
You'd need a second Function running on a timer that could scan your database for rows older than XX minutes ago that still need an event, which then do steps 2 and 3 from your initial flow. In failure scenarios, you will have some potential latency between the data being written and the event published or may see duplicate events. (Event Hubs has an at least once guarantee, so you'll need to be able to handle duplicates regardless.)
QUESTION
I have 3 AWS Elastic Beanstalk instances which are running Spring microservices. All microservices are making POST requests to each other and using RDS service for database.
Should I isolate database traffic and microservices traffic into separate subnets? In case it's a good practice is it possible to assign 2 private network IP's for each subnet for every AWS Elastic Beanstalk instance?
...ANSWER
Answered 2021-Jun-09 at 01:46It's not a good practice to directly communicate between instances in EB. The reason is that that EB instances run in autoscalling group. So they can be terminated and replaced at any time by AWS leading to change in their private Ip addresses.
The change in IP will break your application sooner or later. Instances in EB should be accessed using Load Balancer or private IP.
So if you have some instances that are meant for private access only you could separate them to internal EB environment.
QUESTION
Trying to understand event driven microservices; like in this video. It seems like the basic idea is "producers create tasks that change the state of a system. Consumers read all relevant tasks (from whatever topic they care about) and make decisions off that"
So, if I had a system of jars- say a red, blue, and green jar (topics). And then had producers adding marbles to each jar (deciding color based on random number, let's say). The producers would tell kafka "add a marble to red. Add a marble to blue... etc" Then, the consumers, every time we wanted to count jars would get the entire log and say "ok, a marble was added to red, so redCount++, then a marble was added to blue so blueCount++..." for the dozens/hundreds/thousands of lines that the log file takes up?
That can't be correct; I know it can't be correct. It seems incredibly inefficient; almost anti-efficient!
What am I missing in my knowledge of kafka tasks?
...ANSWER
Answered 2021-Jun-08 at 16:06The data in each of those topics will be retained as per a property log.retention.{hours|minutes|ms}. At the Kafka server level, this is set to 7 days by default for all topics. You could change this at a topic level as well.
In such a setting, a consumer will not be able to read the entire history if it needed to, so in this instance typically a consumer would:
- consume the message i.e. "a marble no. 5 was added to red jar" at offset number 5
- carry out the increment step i.e.
redCount++and store the latest information (redCount = 5) in a local state store - Then commit the offset back to Kafka telling that it has read the message at offset number 5
- Then, just wait for the next message...
If however, your consumer doesn't have a local state store - In this case, you would need to increase the retention period i.e. log.retention.ms=-1 to store the data forever. You could configure the configure the consumers to store that information locally in memory but in the event of failures there would be no choice but for the consumers to read from the beginning. This I agree is inefficient.
QUESTION
We have several microservices built on top of aspnetcore and entity framework and using the MySQL EntityFramework connector from Devart. I've noticed that if the first query that any of our applications attempts fails due to the data store being inaccessible, then the failure seems to be cached, and when the DB is finally alive, the exception is still returned to the user code.
As part of the diagnosis of this problem I tried disabling the database when the application is running and in this situation the application appears to be able to recover once the DB is available again, so I suspect the problem is related to a connection that may be cached during model initialisation.
I've also tried disabling the service provider caching and this also lets the application recover but at the cost of having to initialise the service provider each time, so this can't be used in our application but lends weight to the idea that the error is related to some form of caching.
Has anyone else had/seen this problem before? What was your solution?
Here is a stack trace for context:
...ANSWER
Answered 2021-Apr-15 at 17:09Please try turning off pooling ("Pooling=false;" in the connection string) or clear the pool explicitly with MySqlConnection.ClearAllPools(true).
For more information, refer to:
QUESTION
I use a large RDS database instance that is shared among several different projects (not microservices to be exact) and this database's performance is critical. Hence I monitor the queries whenever support team raise tickets related to performance of our services. So in order for me to track where each query originated from i.e, which app, file and line number, I want to automatically add a SQL comment for all queries. So when I call toSql() on the query builder object it must show me the comment
...ANSWER
Answered 2021-Jun-06 at 16:39Overriding the Grammer class directly may be possible but it internally delegates its work to Database Specific grammer classes
For example if you have configured Mysql in config/database.php then the Grammer class delegates the work on to Illuminate\Database\Query\Grammars\MySqlGrammar
Similarly for Postgres it will be Illuminate\Database\Query\Grammars\PostgresGrammar
Based on the database config the
ConnectionFactory[src/Illuminate/Database/Connectors/ConnectionFactory.php->createConnection()]
loads the proper connection manager for a given database
I am not sure if overriding of this classes is even possible or not because of the PSR-4 loading as the namespace is tightly linked with the physical location of the file in the directory tree
So instead of that I would suggest to go for laravel macros by which you may add new functions to existing classes that use Macroable trait
A POC example can be found below, for further advancement you are encouraged to dig the code for update, insert, delete etc in Grammer.php and Builder.php
QUESTION
I'm currently working on a microservices application for my internship using Consul for service discovery and feign clients for communicating between the services. When we started working on the existing project which already was built using microservices, we upgraded Spring boot to 2.4.3 & cloud to 2020.0.1, so that we could make use of Java 15 to use records instead of normal classes for dtos. The problem we have now is that, whenever we make a call to a composite service, that will try to retrieve data from multiple services (for example users and teams service), that we get the following stacktrace:
...ANSWER
Answered 2021-Jun-04 at 07:23Can you try excluding ribbon dependency as shown below
QUESTION
I'm trying to build sample Service Registration Server using Kotlin & Gradle, when i deploy it locally using intelliJ everything works fine, but when I try to pack it up into docker and launch container I get this:
...ANSWER
Answered 2021-Jun-06 at 12:35dockerfile was poorly constructed, also added main-class config for application in build.gradl.kt
QUESTION
I have successfully exposed two microservices on AWS with Traefik Ingress Controller and AWS HTTPS Load Balancer on my registered domain.
Here is the source code: https://github.com/skyglass-examples/user-management-keycloak
I can easily access both microservices with https url:
...ANSWER
Answered 2021-Jun-03 at 22:30Right - the admin console is listening on 127.0.0.1. This is not the outside world interface. This is "localhost".
You have two choices here. You can start Keycloak with a command line argument like:
Community Discussions, Code Snippets contain sources that include Stack Exchange Network
Vulnerabilities
No vulnerabilities reported
Install microservices
You can use microservices like any standard Java library. Please include the the jar files in your classpath. You can also use any IDE and you can run and debug the microservices component as you would do with any other Java program. Best practice is to use a build tool that supports dependency management such as Maven or Gradle. For Maven installation, please refer maven.apache.org. For Gradle installation, please refer gradle.org .
Support
Reuse Trending Solutions
Find, review, and download reusable Libraries, Code Snippets, Cloud APIs from over 650 million Knowledge Items
Find more librariesStay Updated
Subscribe to our newsletter for trending solutions and developer bootcamps
Share this Page